Data engineering for AI systems is fundamentally different from traditional data engineering. While analytics pipelines are designed to explain what happened, AI systems are responsible for deciding what happens next.
That shift changes everything.
AI systems operate continuously, influence real-world outcomes, and often function without human oversight. Under these conditions, assumptions embedded in data pipelines are no longer harmless. They become decision logic.
As a result, many organizations experience a familiar pattern: models perform well in development but degrade unexpectedly in production. The issue is rarely the model itself. It is the data system supporting it.
Why Data Engineering for AI Systems Is Different
Traditional data engineering evolved for reporting and analytics. These systems tolerate delay, aggregation, and approximation because humans interpret the results.
AI systems operate under a different set of constraints:
- Data must be timely and representative
- Meaning must remain consistent across environments
- Decisions are automated and continuous
- Errors propagate immediately into outcomes
This creates a structural shift. Data is no longer just an input to analysis. It becomes a dependency for decision-making.
Organizations that reuse analytics-era pipelines for AI often create systems that appear functional but are fundamentally fragile.
Why AI Systems Fail in Production
AI failures rarely look like system failures.
Pipelines continue running. Dashboards remain green. Yet outcomes degrade over time.
This happens because failures originate early in the data lifecycle but surface later as:
- declining model performance
- inconsistent decisions
- governance and compliance issues
By the time these issues are detected, they are difficult and expensive to diagnose.
The root cause is almost always the same: the data system was not designed for AI-driven decisions.
The Data Engineering for AI Systems Framework
To address this, a responsibility-based model is required.
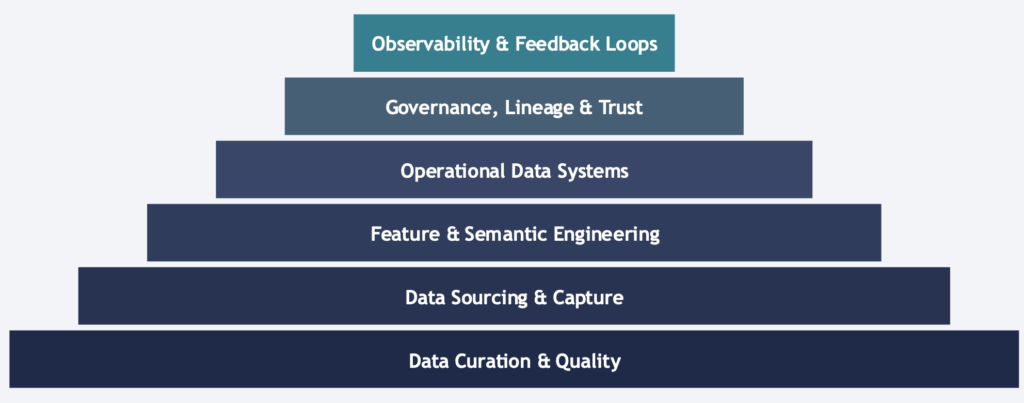
The Data Engineering for AI Systems framework defines six layers that determine whether an AI system can be trusted in production.
These layers are not a technology stack. They are responsibility domains that must be explicitly owned and managed.
👉 Download the Data Engineering for AI Systems whitepaper
The Six Layers of AI Data Engineering
Data Sourcing and Capture
Defines what signals enter the system and at what level of detail. Early decisions about data collection have irreversible consequences. If critical signals are not captured, they cannot be recovered later.
Data Curation and Quality
Ensures data remains fit for decision-making, not just structurally valid. Data can be technically correct while no longer representing real-world conditions.
Feature and Semantic Engineering
Maintains consistent meaning across systems. When feature definitions drift, models behave unpredictably even when infrastructure appears stable.
Operational Data Systems
Delivers data under real-time constraints. Latency is not just a performance issue. It directly impacts decision quality.
Governance, Lineage, and Trust
Ensures decisions are traceable and accountable. Governance must extend beyond datasets to include decision logic and outcomes.
Observability and Feedback Loops
Detects degradation and enables adaptation. Monitoring predictions alone is insufficient. Systems must observe real-world outcomes.
How Failures Propagate Through AI Systems
Failures in AI systems rarely surface where they originate. Small decisions made early in the data lifecycle propagate upward through the system and appear later as model or business issues.
This is why retraining models often fails to resolve systemic problems. It addresses symptoms rather than causes.
👉 Download the Data Engineering for AI Systems whitepaper
Common Anti-Patterns in AI Data Engineering
- Treating AI as a modeling problem
- Reusing analytics pipelines for real-time decisions
- Allowing feature definitions to drift
- Governing data but not decisions
- Monitoring predictions instead of outcomes
Measuring AI Beyond Model Accuracy
Model accuracy alone is not enough. Effective AI systems must be evaluated across three dimensions:
- Value — Are decisions improving outcomes?
- Risk — Are decisions compliant and explainable?
- Reliability — Can degradation be detected and corrected quickly?
What This Means for Organizations
AI success is not just about better models or better tools. It requires clear ownership, alignment across teams, and explicit responsibility for data assumptions.
Organizations that succeed with AI do not eliminate complexity. They make responsibility visible and manageable.
Final Thought
AI readiness is not a milestone. It is an engineering discipline.
Systems that hold up over time are not those with the most advanced models, but those with the clearest understanding of how data, decisions, and outcomes are connected.
Download the Full Framework
If you want the complete framework, including diagnostic tools, anti-patterns, and a 30-day implementation playbook:
